










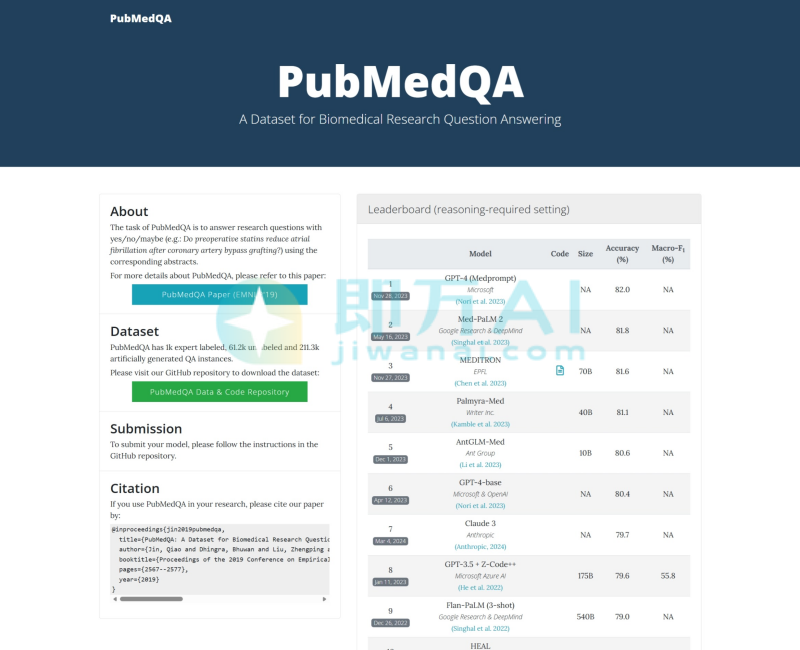
PubMedQA是什么
PubMedQA是一个用于评估AI在生物医学文献理解与推理能力的问答数据集。其核心任务是:给定一篇 PubMed论文的摘要(不含结论部分)和一个研究问题(通常来自论文标题),模型需判断答案是“是(yes)”、“否(no)”还是“可能/不确定(maybe)”,并给出依据。数据集由匹兹堡大学团队于2019年发布,包含1,000条专家人工标注样本,被广泛用于测试大模型是否具备类似科研人员的逻辑推理能力。其优势在于问题源于真实科研场景、答案需基于证据推理、且有高质量人工标注作为标准。
PubMedQA的主要功能
- 提供标准化评测基准:通过统一的任务定义和评估指标(准确率、Macro-F1),支持不同模型间的公平比较。
- 包含高质量人工标注子集(PQA-L):1,000条由医学背景人员标注的数据,用于可靠测试,不依赖自动标签。
- 支持科学推理能力验证:问题设计要求模型理解实验设计、统计结果(如p值、置信区间)并进行逻辑推断,而非简单关键词匹配。
- 开放数据与代码:完整数据集、基线模型和评估脚本在GitHub开源,便于学术复现。
- 划分多子集适配不同训练策略:含人工标注(L)、未标注(U)和自动生成(A)三部分,支持半监督或预训练研究。
PubMedQA官网地址:
官网:pubmedqa.github.io
PubMedQA的应用场景
- 大模型医学能力评测:如 Med-PaLM、GPT-4、Claude 等模型在发布前常在此测试其循证推理水平。
- 学术研究基准:自然语言处理(NLP)与计算生物医学领域论文的标准测试集之一。
- 模型开发与微调:研究者用其训练更可靠的医学问答系统,尤其关注减少“幻觉”和提升证据意识。
- 教学与课程实验:高校AI或生物信息学课程中用于讲解科学问答、证据推理等概念。
- 医疗AI产品验证参考:企业用其子集检验自家系统是否能像医生一样基于文献做判断。
PubMedQA常见问题有哪些
- 这是个在线工具吗?能直接提问吗?
不是。它是一个研究用数据集,需下载后配合模型使用,不能像ChatGPT那样直接交互问答。 - 为什么答案只有 yes/no/maybe?
这是为了模拟科研中对假设的判断,结论要么支持、要么否定、要么证据不足,符合真实科研逻辑。 - “maybe”多吗?代表什么?
约占15%–20%,表示摘要中缺乏明确结论、样本量小、结果矛盾等,体现科学研究的不确定性。 - 中文用户能用吗?
数据全为英文,但因结构清晰、任务明确,国内高校和企业研究团队广泛采用;需基础英文阅读能力。 - 和临床诊断有关吗?
无关。它测试的是对科研文献的理解,不是患者症状诊断;不适用于直接回答“我头疼是不是脑瘤”这类问题。 - 最新SOTA成绩多少?
截至2025年底,龙尔平/万沛星团队提出的MCC框架在PubMedQA上达到84.8%准确率;人类专家平均约为78%。
相关导航
暂无评论...