










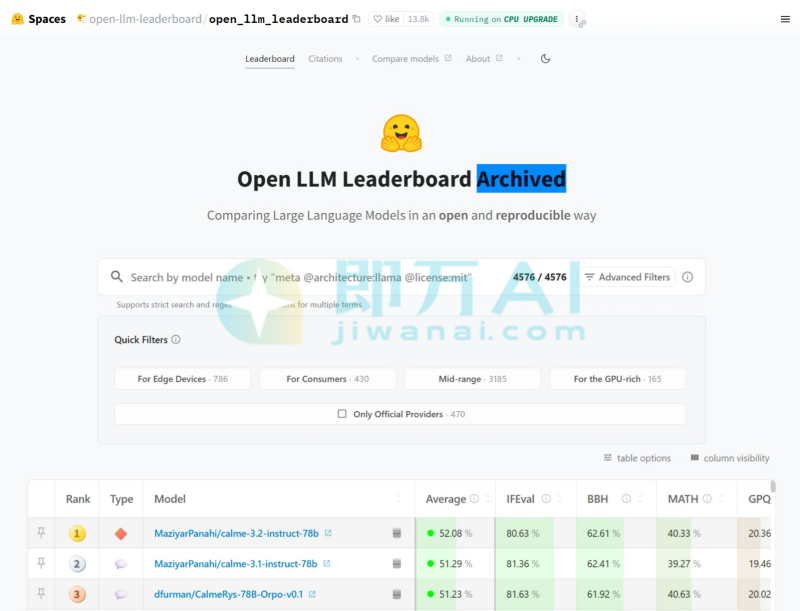
Open LLM Leaderboard是什么
OpenLLMLeaderboard是HuggingFace推出的AI大模型综合排名与评估平台。整合多个权威学术基准(如ARC、HellaSwag、MMLU、TruthfulQA等),对公开可访问的大语言模型进行统一评测并排名,能直观呈现模型的综合得分及细分任务表现。支持社区提交符合要求的模型参与评测,所有结果公开可查;采用动态更新机制,可持续纳入新模型与数据,避免时效性不足问题;还提供模型得分breakdown、任务示例等详细数据,助力用户深入分析模型优势与短板。为用户提供对比不同开源大模型的性能,为模型选型、优化、研究提供可靠参考,同时缓解评测碎片化问题。
Open LLM Leaderboard的主要功能
- 自动评测主流英文基准:集成7个核心数据集,包括:ARC(科学常识)HellaSwag(情境推理)MMLU(多任务知识)TruthfulQA(事实准确性)Winogrande(指代消解)GSM8K(数学推理)BBH(Big-Bench Hard,复杂推理)
- 统一评估协议:所有模型使用相同提示模板、采样参数(temperature=0.1, max_new_tokens=1024)和评估脚本,确保公平性。
- 实时更新排行榜:新模型上传至Hugging Face Hub后,若符合格式要求,系统自动触发评测并更新排名。
- 开放提交机制:任何用户均可上传兼容模型(支持AutoModelForCausalLM),无需审核即可参与评测。
- 详细分数拆解:展示各子任务得分及总体平均分(Average Score),便于分析模型强弱项。
- 仅限英文评估:当前所有测试均为英文,不包含中文或其他语言任务。
Open LLM Leaderboard官网地址:
官网:huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
Open LLM Leaderboard的应用场景
- 开源模型选型:开发者快速比较Llama、Qwen、Mistral、Gemma等系列模型的综合能力。
- 研究论文基线参考:学术团队将新模型在此榜单上测试,作为性能对比依据。
- 社区贡献激励:鼓励开发者优化模型并提交,通过公开排名获得技术认可。
- 教学与科普:用于讲解大模型能力差异、评测方法及开源生态发展。
- 企业技术预研:AI团队初步筛选适合微调或部署的底座模型。
Open LLM Leaderboard常见问题有哪些
- 能测中文模型吗?
不能。所有评测任务均为英文,中文模型(如Qwen、ChatGLM)在此表现通常偏低,不代表其中文能力。 - 结果可信吗?
在英文通用能力范围内可信;但因仅用零样本(zero-shot)设置,未反映微调或指令优化后的实际效果。 - 为什么有些知名模型没上榜?
可能因模型未发布到Hugging Face Hub,或不符合自动评测的架构要求(如非causal LM)。 - 支持多模态或代码模型吗?
不支持。仅评测纯文本生成式语言模型(decoder-only架构)。 - 和OpenCompass、HELM比有什么区别?
Open LLM Leaderboard全自动、轻量级;OpenCompass/HELM覆盖更广(含中文、多模态、主观评测),但更新频率较低。 - 有API或数据下载吗?
排行榜数据可通过Hugging Face Spaces公开访问,完整结果CSV可在GitHub仓库(huggingface/open-llm-leaderboard)获取。
相关导航
暂无评论...